
An updated version of this blog post is now available as a chapter in the TopBraid Application Development Quickstart Guide (pdf).
TopBraid includes the D2RQ interface to relational database management systems and automates most of the configuration for you, giving your TopBraid applications easy access to relational data. In this entry, we'll see how easily a SPARQLMotion script can use data stored in a MySQL database. You would use a similar process to get at data stored using Oracle, Sybase, SQL Server, and PostgreSQL. Our sample uses MySQL's sample "world" database, a collection of data about countries around the world. See the Other MySQL Documentation page to download the database and for information on installing it.
Configuring TopBraid to read a MySQL database
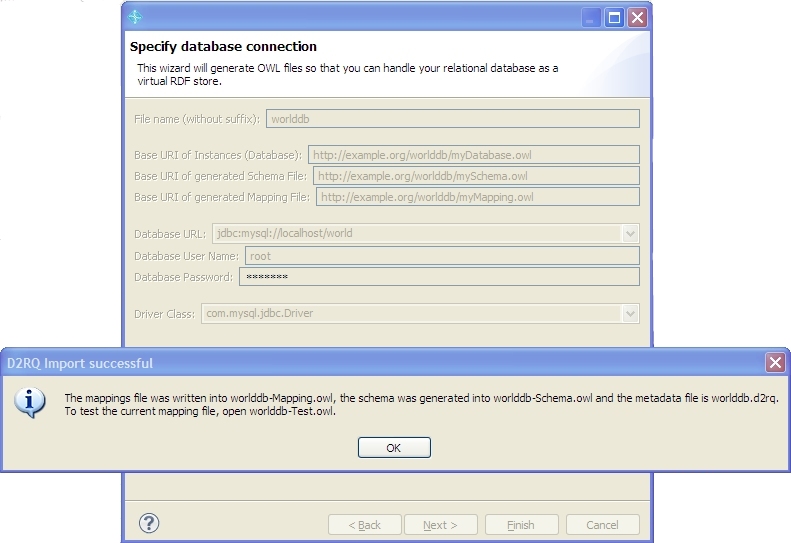
Once you have a running copy of MySQL with the world database installed, the next step is to tell TopBraid Composer to create the configuration files that let you treat this relational database as a virtual triplestore. Start by selecting the project or folder in the Navigator window where you want TBC to put these files, and then select Import from the File menu and pick "RDF/OWL View on Relational Database via D2RQ" from the list of formats that can be imported. Click the Next button, and you'll see the Specify database connection dialog box.
For the database connection file name, enter worlddb, and then change the Base URI of each of the configuration files to something that reflects this filename, as shown in the screen shot below.
The last four fields are where you specify the key information for giving TopBraid access to the database. The drop-down list for the Database URL field offers a choice of templates for different RDBMS systems; for our MySQL database, select jdbc:mysql://<server>/<database> and change it to jdbc:mysql://localhost/world. (This assumes that MySQL is running on the same machine as your copy of TBC. If not, substitute the appropriate name for localhost. The part after the last slash is the database that you want to read from the MySQL server on that system.) In the next two fields, enter a user name and password for an account that has access to the worlddb database when using MySQL tools, and then in the Driver Class field select com.mysql.jdbc.Driver.
Click the Finish button, and TBC will create the configuration files and display a message box about it:
The "Importing Relational Databases with D2RQ" online help panel has good background on this whole process, especially on the role that each of these configuration files play. Among other things, it points out that the property names assigned to the columns of the relational database tables are just a starting point that can be reconfigured by editing these files. For example, the tableName_columnName format of the property names that you use to access the data is only a default and can be changed.
Reading the data from a SPARQLMotion script
To see how SPARQLMotion can use this data, we're going to create a simple script that gets the database's value for the president of the United States. After running it, we'll update the data using a MySQL tool and then run the SPARQLMotion script again to see the update reflected in the data that TopBraid is using.
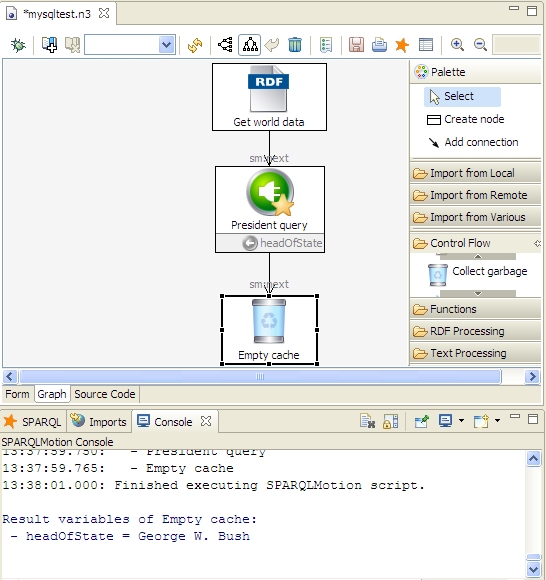
Start by creating a new SPARQLMotion file as described at How to: create and run a SPARQLMotion script and call it mysqltest. Create a new SPARQLMotion script for this file, and for its initial module pick sml:ImportRDFFromWorkspace from the sml:ImportFromLocalModules section of the sml:ImportModules category. Call it GetWorldData, and when its icon appears, set this module's sml:sourceFilePath property to worlddb-Test.owl. This was one of the files created earlier by the configuration process, and it imports two others: the worlddb-Schema.owl schema file and the worlddb.d2rq file that serves as a placeholder for the actual data in the MySQL world database. This is the only property that you need to set for this module.
Next, we'll add a module that queries the database for the name of the president of the United States. Add a Bind by select module from the Control Flow section of the SPARQLMotion palette and call it PresidentQuery. Set its sml:selectQuery property to the following query (note how the namespace for the property names is the "Base URI of generated Schema file" value you assigned when configuring how TopBraid would import the MySQL data):
PREFIX w: <http://example.org/worlddb/myschema.owl#>
SELECT ?headOfState
WHERE {
?s w:country_Name "United States" .
?s w:country_HeadOfState ?headOfState .
}
That's the only property to set for this module, so close the Edit PresidentQuery dialog box, click Add connect on the SPARQLMotion palette, and connect the GetWorldData module icon to the new icon.
When you work with a database like this, TopBraid keeps cached copies of the data to speed up later queries on the same data. This has obvious advantages, but it can be a disadvantage if you're more interested in data currency than in quick retrieval times. Our database is small, and we want to see changes reflected as soon as possible, so we're going to add a module that clears out this cache each time the script is run.
Drag a Collect garbage module from the Control Flow section of the palette to your workspace and name it EmptyCache. Set its sml:baseURI property to the URI for the database you want to clear from the cache: http://example.org/worlddb/myDatabase.owl, which is the base URI for the worlddb.d2rq placeholder file. (This is the URI you entered in the "Base URI of Instances (Database)" field when you set up the initial import and configuration.) After configuring this one property, connect the President query module icon to the Empty cache icon.
Select the Empty cache icon and click the debug icon to run this short script. You'll see in the Console view (a handy view when developing and debugging scripts) that the headOfState property has the value "George W. Bush", so the MySQL sample database is a bit out of date:
Let's fix this. Update the data using your favorite MySQL tool. For example, from MySQL's command line interface, you could enter this:
mysql> USE world
Database changed
mysql> UPDATE country SET HeadOfState="Barack Obama"
-> WHERE HeadOfState="George W. Bush";
Run the SPARQLMotion script again, and you should see the update reflected in the Console view. If it wasn't for the script's Empty cache icon, your SPARQL query might have used a cached copy of the data that did not include this updated value.
As the online help tells us, it's a good idea to be careful with the sml:CollectGarbage module, especially if you're developing a multi-user application where data is frequently updated. If quick access to updated data is not a priority in your application, omitting this module will mean faster response times for your users. It's up to the needs of your application, and it's good to know that you can have it either way.
Instead of opening the worlddb-Test.owl file with your application, you're more likely to open a file that you created that imports one or more of the configuration files generated above (again, read the "Importing Relational Databases with D2RQ" help panel to learn more about what each file can contribute to your application) and perhaps some other files as well. You could add additional data files and RDFS or OWL files describing relationships between the various imported files so that you can do interesting things with the combinations. For example, you could declare the properties that reference MySQL database columns to be subproperties of others declared for your application or declared in a standard vocabulary such as Dublin Core.
Something else that can make your script development easier is importing the generated schema into your script—in this case, dragging the worlddb-Schema.owl file onto the Import view of the mysqltest file. This way, the namespace prefixes will already be defined for you and you can use autocompletion when you enter class and property names in your SPARQL queries.
The sample application here didn't do much on its own, but when you combine the imported data with other data and metadata and take advantage of the other techniques described in this How-to series, the ability to incorporate live relational data in your semantic web applications adds some great possibilities to what your applications can do.



0 comments:
Post a Comment